均值算法
jedec
except
测试用例
nlp
图书馆座位预约
项目管理
abapgit
心理健康管理系统
python学习资料
C++语法,动态绑定
信息系统综合测试与管理
skill command
安全框架
elf
深浅拷贝
tornado
分布式光纤测温
飞书
线程
语音
2024/4/11 15:19:46
QtApplets-QTextToSpeechDemo
QtApplets-QTextToSpeechDemo
哎呀妈呀,这个系列应该有好长一段时间没有更细了,因为啥呢,主要是因为这一段时间都在折腾Debian 10 下的软件开发,都是在调试代码,实在是没有啥新功能需要试验的,有的也是在L…

从“连接”到“交互”——阿里巴巴智能对话交互实践及范式思考
作者简介:孙健,博士,阿里巴巴iDST 自然语言理解和人机对话负责人,资深专家。 导读:传统互联网时代体现出来的更多的是“连接”,现如今,随着智能设备的增加,人和设备逐渐走向“交互”…
程序运行时增加语音提示
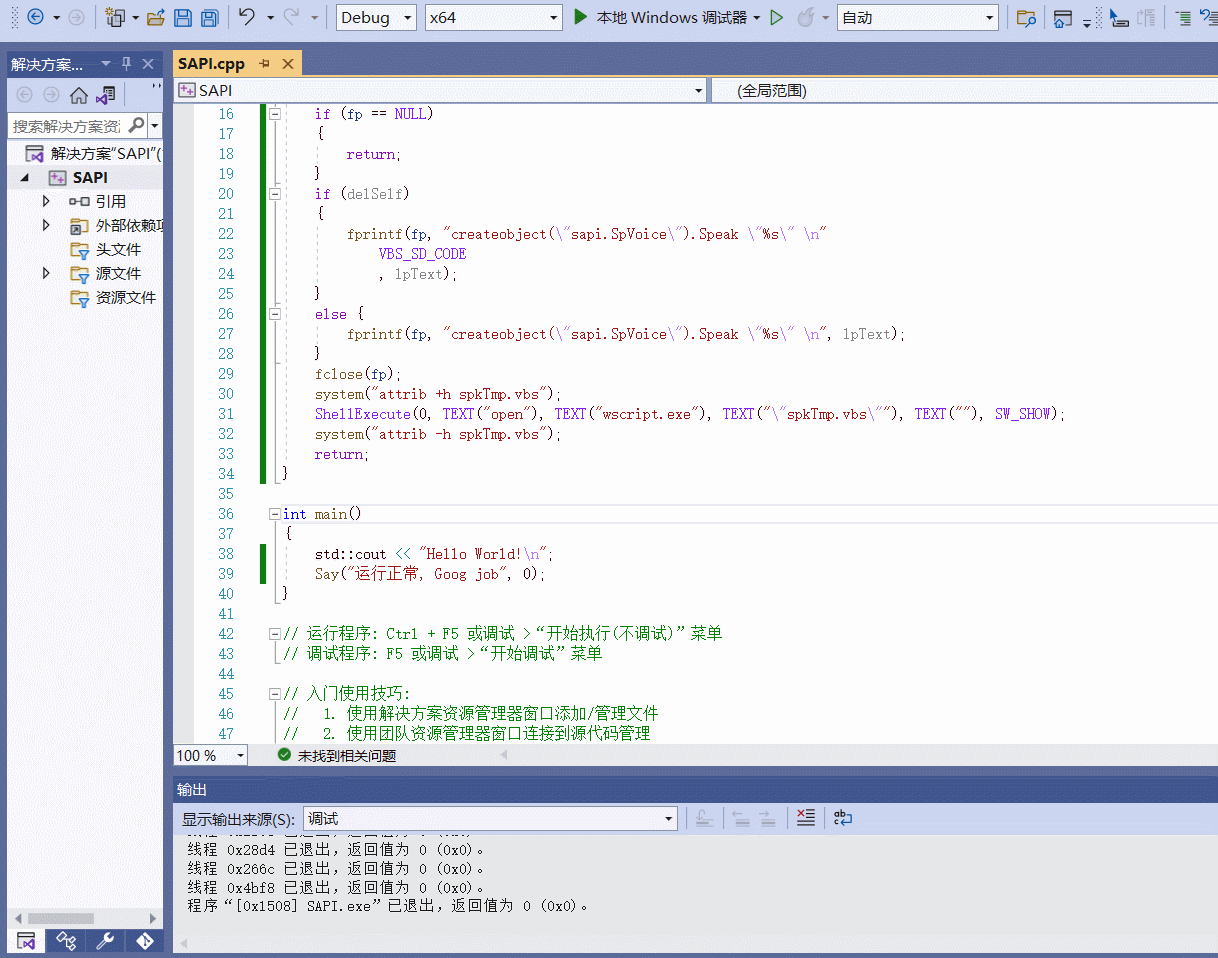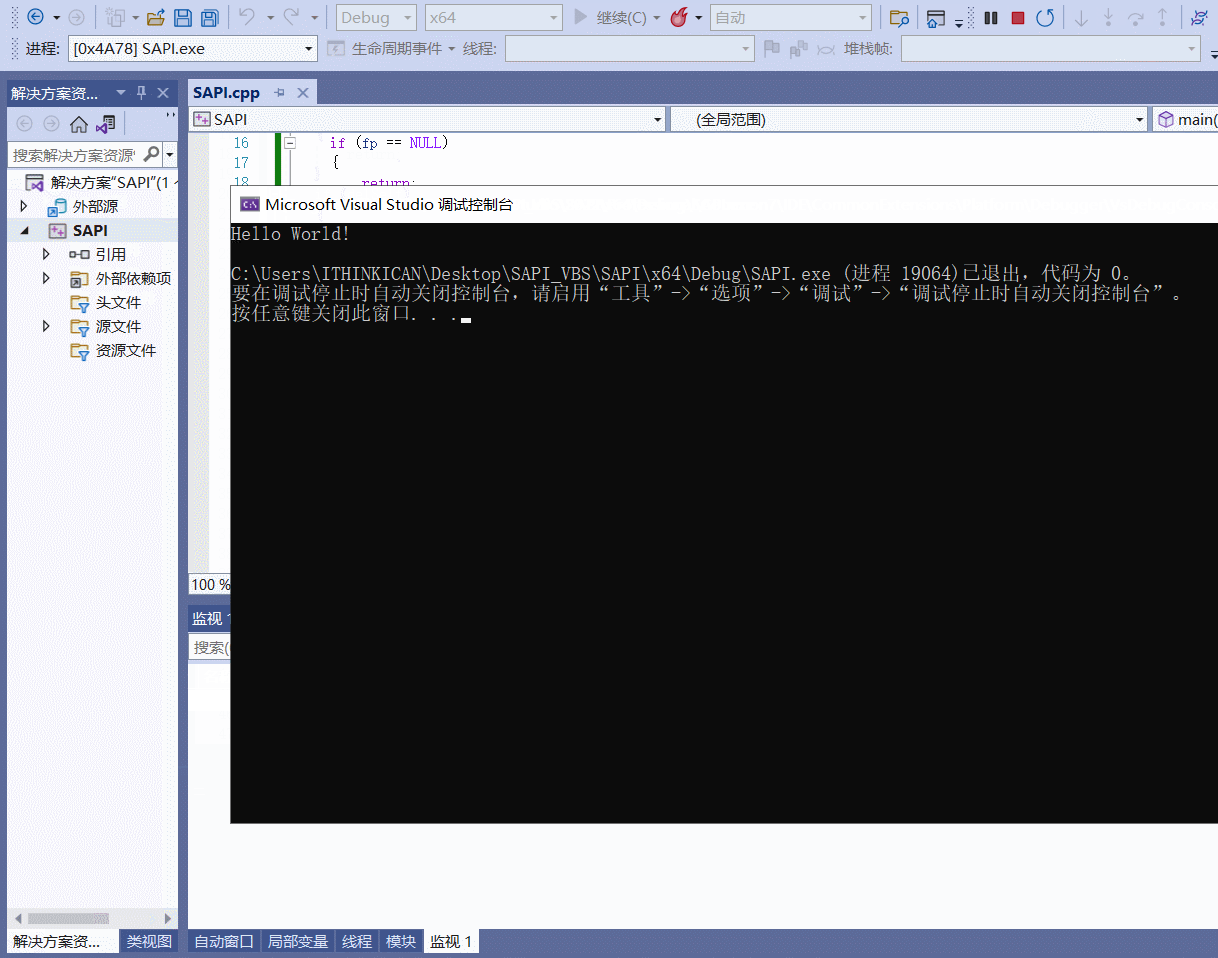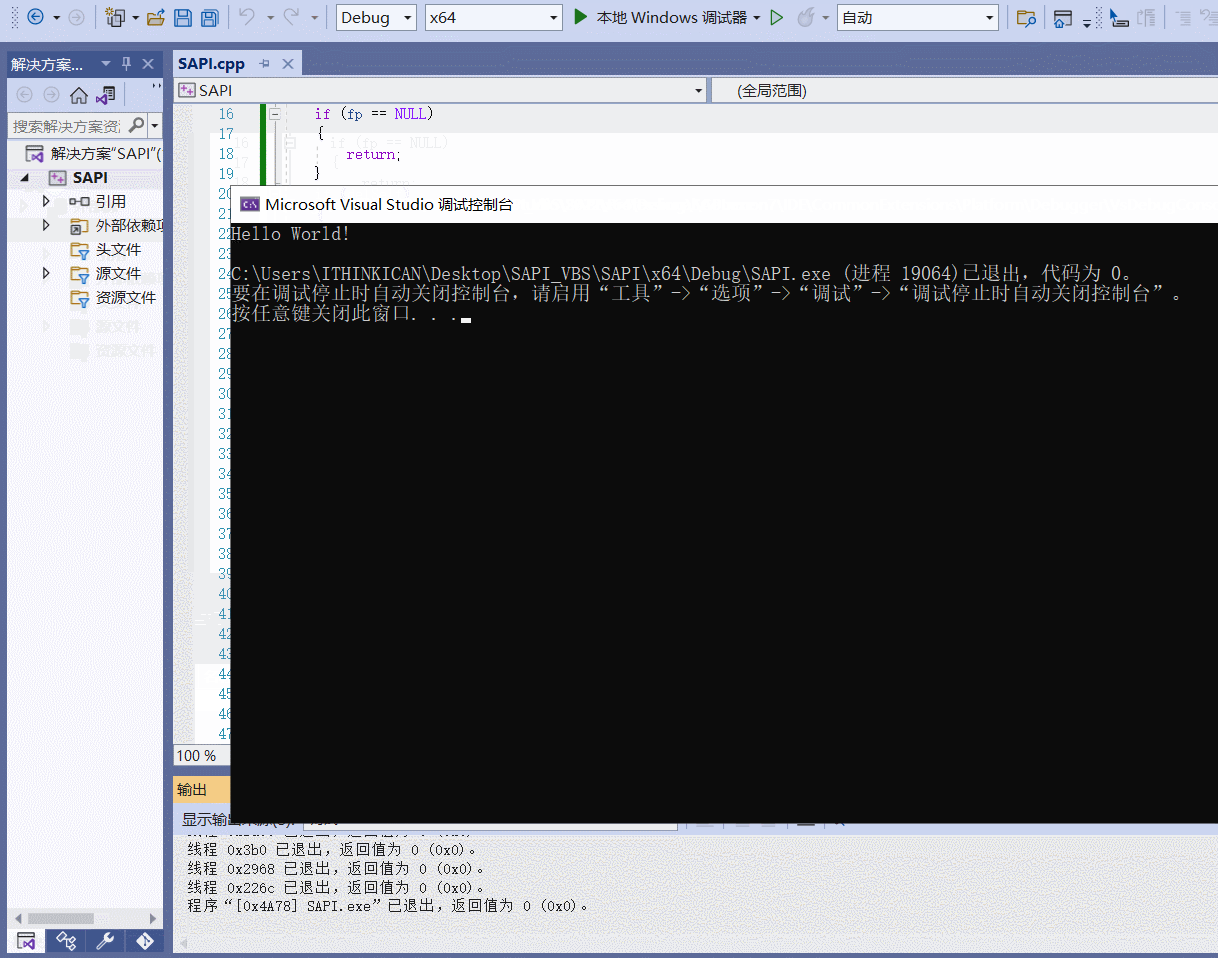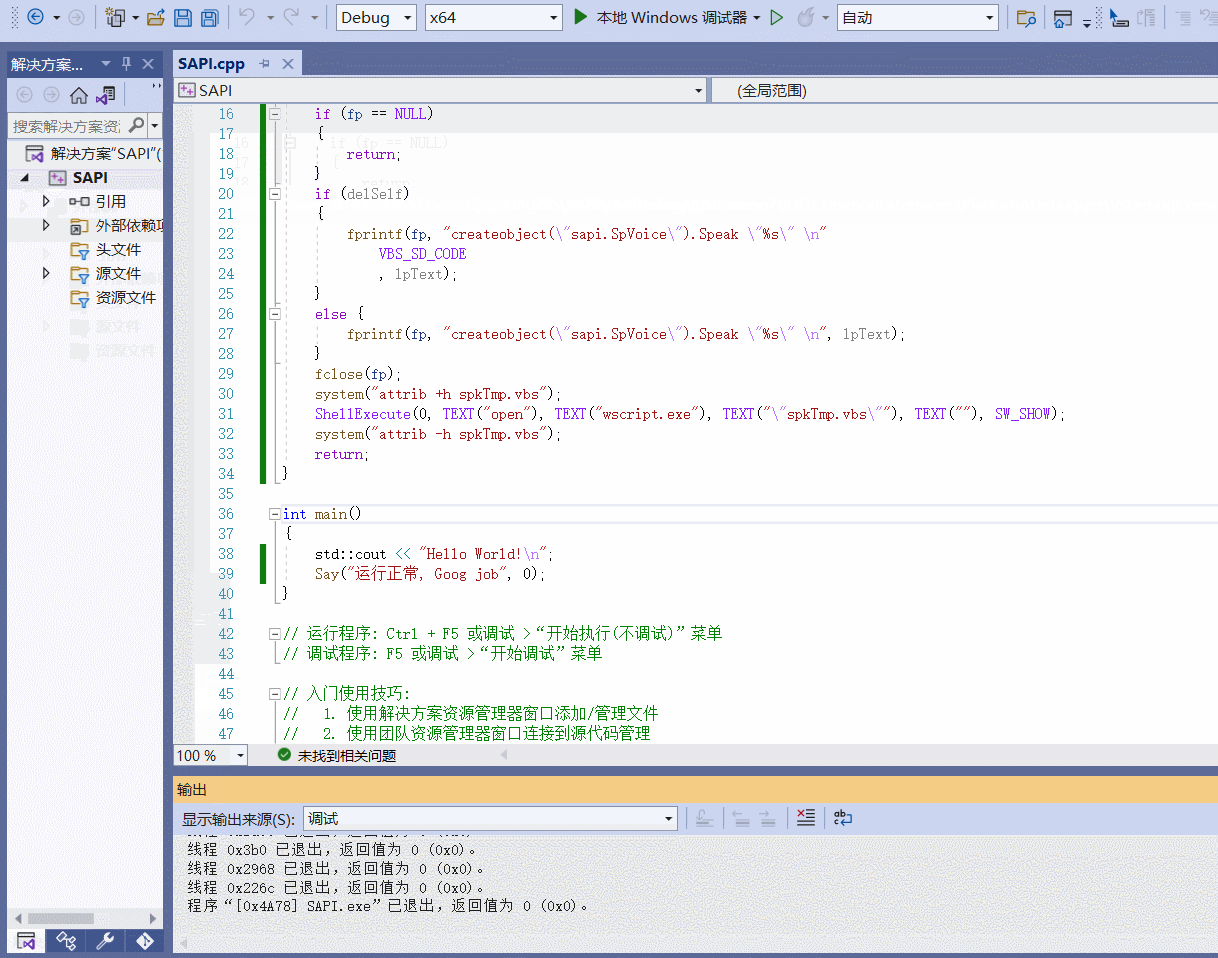
目录 前言 一、认识SAPI 二、使用方法 三、测试效果编辑 总结 前言
在测试过程中为了更高效的提示操作者,在程序执行时增加语音提醒会方便很多,利用微软的SAPI可以很方便的在程序有问题时提示操作者。 一、认识SAPI
SpVoice类是支持语音合成(TTS)的核…

vb6测试操作系统是否支持TTS语音朗读功能
Function TTsTest(Optional Str1 As String "ABC123逍遥语音朗读工具测试") As BooleanOn Error GoTo Err1Dim Voice As SpVoiceSet Voice New SpVoiceSet Voice.Voice Voice.GetVoices("", "Language804").Item(0) 中文朗读Voice.Speak Str1…
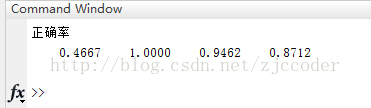
【神经网络学习笔记】BP神经网络-语音特征信号分类
%% 清空环境变量
clc
clear%% 训练数据预测数据提取及归一化%下载四类语音信号
load data1 c1
load data2 c2
load data3 c3
load data4 c4%四个特征信号矩阵合成一个矩阵
data(1:500,:)c1(1:500,:);
data(501:1000,:)c2(1:500,:);
data(1001:1500,:)c3(1:500,:);
data(1501:20…

人工智能与欺诈:语音伪造的隐患与欺诈新时代
现代人工智能 (AI) 技术已达到先进水平,可以从简短的录音片段中生成极其逼真的音频消息。
这一新技术前沿也被网络犯罪分子利用,他们通过获取个人录音来训练神经网络来创建伪造的音频消息。这些消息的目的是欺骗受害者的朋友和家人,通常用于…
调用Win10隐藏的语音包
起因
在做一个文本转语音的Demo的时候,遇到了语音包无法正确被Unity识别的问题。明明电脑上安装了语音包但是代码就是识别不出来
原因
具体也不是非常清楚,但是如果语言包是在的话,大概率是Win10系统隐藏了。
确定语言包
首先查看%windi…

Python实现简单的读文字发音
使用pyttsx3包,先安装。 核心代码:engine pyttsx3.init() # 初始化 uname "周吴郑王" engine.say("奥利给给给" str(uname) "的" str(uname) ",感谢!!!") e…
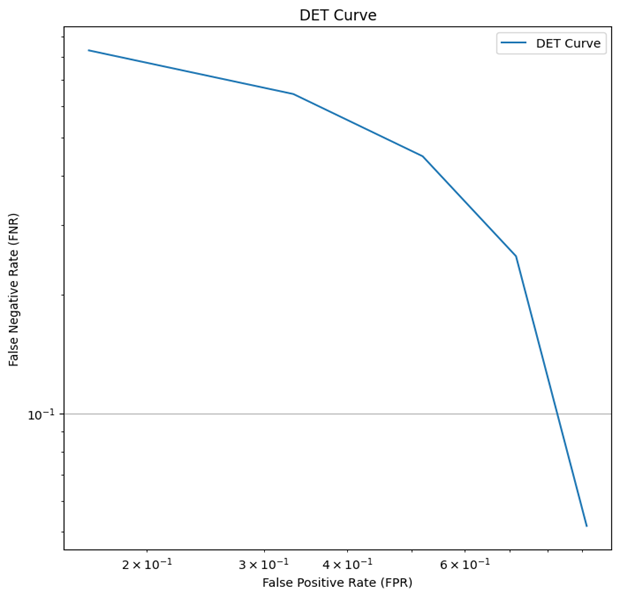
基于WEKWS模型的语音唤醒关键词识别
一、模型描述
1.1 论文解读
本文所使用的模型网络结构继承自论文《Compact Feedforward Sequential Memory Networks for Small-footprint Keyword Spotting》,文中研究了将低秩矩阵分解与传统FSMN相结合的紧凑型前馈顺序记忆网络(cFSMN)用…
【工具】转码silk格式为mp3
【工具】转码slk格式为mp3 前提 安装 ffmpeg
【安装】Linux安装ffmpeg_linux安装ffmpeg4.4_我是Superman丶的博客-CSDN博客 GitHub - kn007/silk-v3-decoder: [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to o…

探索 Web API:SpeechSynthesis 与文本语言转换技术
一、引言
随着科技的不断发展,人机交互的方式也在不断演变。语音识别和合成技术在人工智能领域中具有重要地位,它们为残障人士和日常生活中的各种场景提供了便利。Web API 是 Web 应用程序接口的一种,允许开发者构建与浏览器和操作系统集成的…
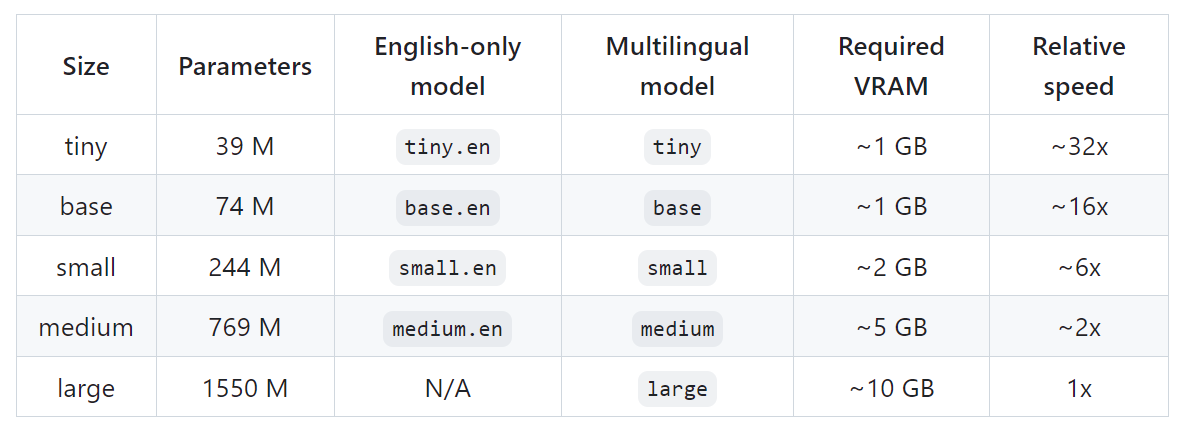
语音识别模型whisper的参数说明
一、whisper简介:
Whisper是一种通用的语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
二、whisper的参数
1、-h, --help
查看whisper的参数
2、--model {tiny.en…